1. Introduction 📑¶
This notebook is just me being frustrated on deep learning and trying to understand in "baby steps" what is going on here. For somebody that starts in this area with no background whatsoever it can be very confusing, especially because I seem to be unable to find code with many explanations and comments.
So, if you are frustrated just like I was when I started this stuff I hope the following guidelines will help you. I am by no means a teacher, but in this notebook I will:
- Share articles/videos I watched that TRULY helped
- Explain code along the way to the best of my ability

2. Before we start ✋¶
This is my second notebook in the "series": How I taught myself Deep Learning.
- How I taught myself Deep Learning: Vanilla NNs
* PyTorch and Tensors * Neural Network Basics, Perceptrons and a Plain Vanilla Neural Net model * MNIST Classification using FNN * Activation Functions * Forward Pass * Backpropagation (Loss and Optimizer Functions) * Batching, Iterations and Epochs * Computing Classification Accuracy * Overfitting: Data Augmentation, Weight Decay, Learning Rate, Dropout() and Layer Optimization- Recurrent Neural Networks and LSTMs Explained
* 1 Layer RNNs * Multiple Neurons RNN * Vanilla RNN for MNIST Classification * Multilayer RNNs * Tanh Activation Function * Multilayer RNN for MNIST * LSTMs and Vanishing Gradient Problem * Bidirectional LSTMs * LSTM for MNIST Classification
3. Convolutional Neural Networks 🏕🏞🛤🏜🏖🏝🏔¶
Pro Tip: Use this tool to create your own convolutional neural nets.
3.1 Why FNNs might not be the best approach 🤔¶
For image classification, Feed Forward Neural Nets are not the best approach for a number of reasons:
They do not take the 2D geometry of the image into account. This means there is no notion of proximity. The human eye detects features in an image locally, meaning that it looks at portions of a picture and recognizes patterns, whereas FNNs don't. Instead, 1 neuron in the Hidden layer connects with ALL pixels from the image, NO matter their position in that image.

FNNs require many connections, therefore they have many weights (parameters) to compute. For example, if we have a 100x100 pixel image => 10,000 neurons in the first layer. If the second layer has 500 neurons, then we end up with 10,000x500 = 5,000,000 weights. Hence, there is large computing cost.
FNNs are prone to overfitting. This means they learn some features very well instead of learning to generalize.
3.2 Youtube Videos to save you time: 🎥¶
Watch these 2 Youtube videos to grasp a better understanding of CNNs.

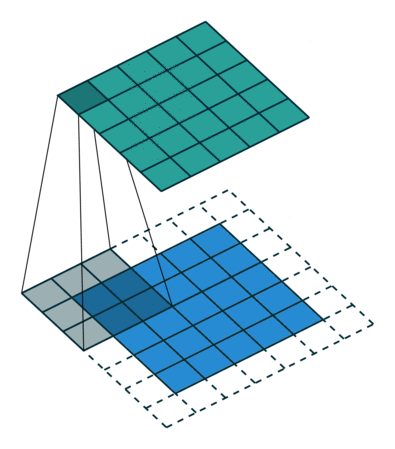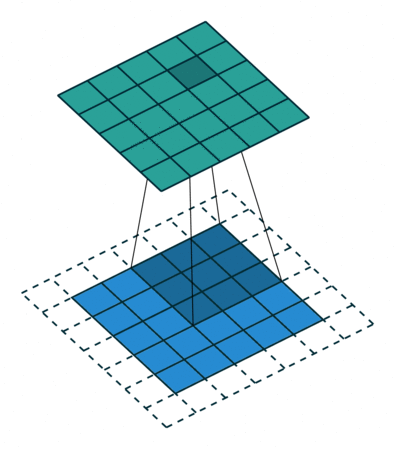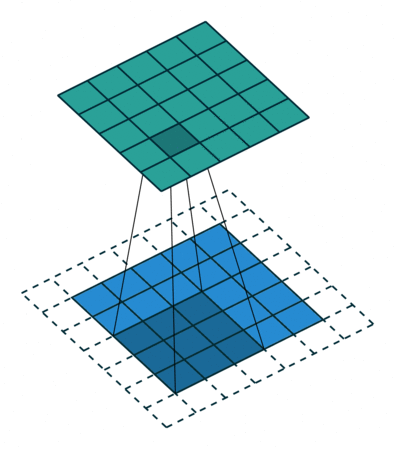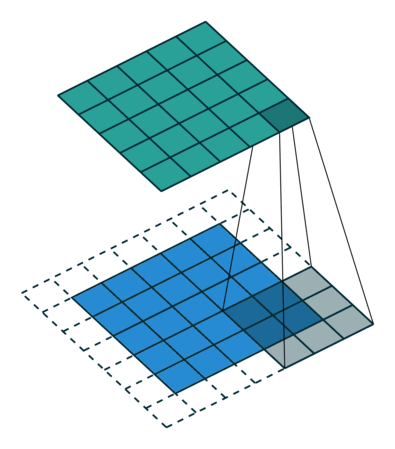
3.3 Convolutions¶
Convolutions solve the issues encoutered by FNNs:
- they take spatial structure into account
- they are made up by weights which learn to identify patterns and fire when they find one
- same weights are used for the entire image (weight sharing)
- you can specify multiple features in one convolutional layer
So: convolutional layers have multiple filters, composed by weights, that learn patterns in the data by sliding over the entire image.

Filters (like neurons in human visual cortex) in smaller layers detect edges, lines, and as the layers increase they start detecting shapes, patterns and even faces/ objects.
3.4 Computing a convolutional kernel 🧾🖊¶
Convolutional Filter == Convolutional Layer == Kernel == Filter
Feature Map == Activation Map