Process Outline¶
Here is the figure shown in class that describes the different components in an ML Metadata store:
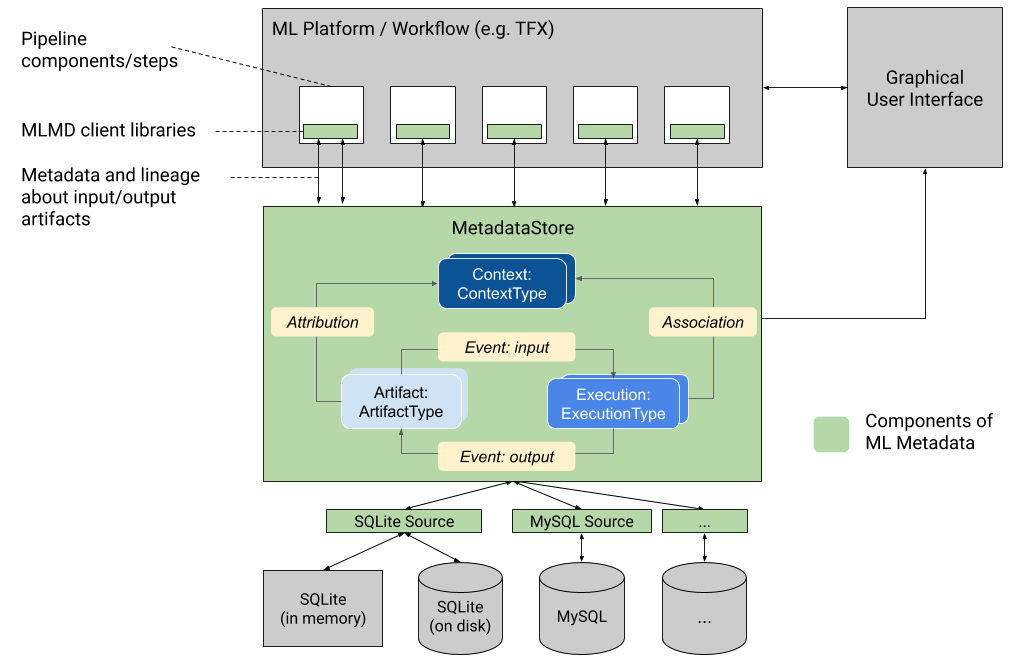
The green box in the middle shows the data model followed by ML Metadata. The official documentation describe each of these and we'll show it here as well for easy reference:
ArtifactTypedescribes an artifact's type and its properties that are stored in the metadata store. You can register these types on-the-fly with the metadata store in code, or you can load them in the store from a serialized format. Once you register a type, its definition is available throughout the lifetime of the store.- An
Artifactdescribes a specific instance of an ArtifactType, and its properties that are written to the metadata store. - An
ExecutionTypedescribes a type of component or step in a workflow, and its runtime parameters. - An
Executionis a record of a component run or a step in an ML workflow and the runtime parameters. An execution can be thought of as an instance of an ExecutionType. Executions are recorded when you run an ML pipeline or step. - An
Eventis a record of the relationship between artifacts and executions. When an execution happens, events record every artifact that was used by the execution, and every artifact that was produced. These records allow for lineage tracking throughout a workflow. By looking at all events, MLMD knows what executions happened and what artifacts were created as a result. MLMD can then recurse back from any artifact to all of its upstream inputs. - A
ContextTypedescribes a type of conceptual group of artifacts and executions in a workflow, and its structural properties. For example: projects, pipeline runs, experiments, owners etc. - A
Contextis an instance of a ContextType. It captures the shared information within the group. For example: project name, changelist commit id, experiment annotations etc. It has a user-defined unique name within its ContextType. - An
Attributionis a record of the relationship between artifacts and contexts. - An
Associationis a record of the relationship between executions and contexts.
As mentioned earlier, you will use TFDV to generate a schema and record this process in the ML Metadata store. You will be starting from scratch so you will be defining each component of the data model. The outline of steps involve:
- Defining the ML Metadata's storage database
- Setting up the necessary artifact types
- Setting up the execution types
- Generating an input artifact unit
- Generating an execution unit
- Registering an input event
- Running the TFDV component
- Generating an output artifact unit
- Registering an output event
- Updating the execution unit
- Seting up and generating a context unit
- Generating attributions and associations
You can then retrieve information from the database to investigate aspects of your project. For example, you can find which dataset was used to generate a particular schema. You will also do that in this exercise.
For each of these steps, you may want to have the MetadataStore API documentation open so you can lookup any of the methods you will be using to interact with the metadata store. You can also look at the metadata_store protocol buffer here to see descriptions of each data type covered in this tutorial.