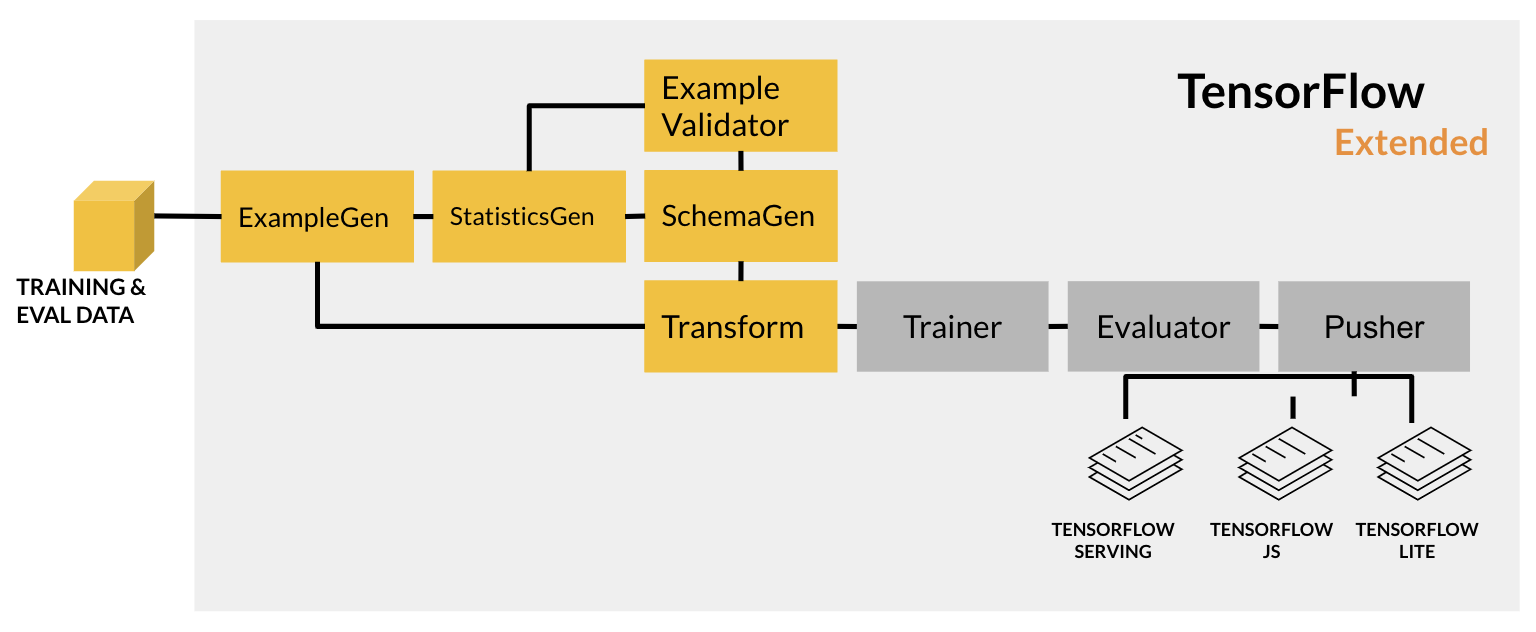
Ungraded Lab: Feature Engineering Pipeline¶
In this lab, you will continue exploring Tensorflow Transform. This time, it will be in the context of a machine learning (ML) pipeline. In production-grade projects, you want to streamline tasks so you can more easily improve your model or find issues that may arise. Tensorflow Extended (TFX) provides components that work together to execute the most common steps in a machine learning project. If you want to dig deeper into the motivations behind TFX and the need for machine learning pipelines, you can read about it in this paper and in this blog post.
You will build end-to-end pipelines in future courses but for this one, you will only build up to the feature engineering part. Specifically, you will:
- ingest data from a base directory with
ExampleGen - compute the statistics of the training data with
StatisticsGen - infer a schema with
SchemaGen - detect anomalies in the evaluation data with
ExampleValidator - preprocess the data into features suitable for model training with
Transform
If several steps mentioned above sound familiar, it's because the TFX components that deal with data validation and analysis (i.e. StatisticsGen, SchemaGen, ExampleValidator) uses Tensorflow Data Validation (TFDV) under the hood. You're already familiar with this library from the exercises in Week 1 and for this week, you'll see how it fits within an ML pipeline.
The components you will use are the orange boxes highlighted in the figure below: