Ungraded Lab: TFDV Exercise¶
In this notebook, you will get to practice using TensorFlow Data Validation (TFDV), an open-source Python package from the TensorFlow Extended (TFX) ecosystem.
TFDV helps to understand, validate, and monitor production machine learning data at scale. It provides insight into some key questions in the data analysis process such as:
What are the underlying statistics of my data?
What does my training dataset look like?
How does my evaluation and serving datasets compare to the training dataset?
How can I find and fix data anomalies?
The figure below summarizes the usual TFDV workflow:
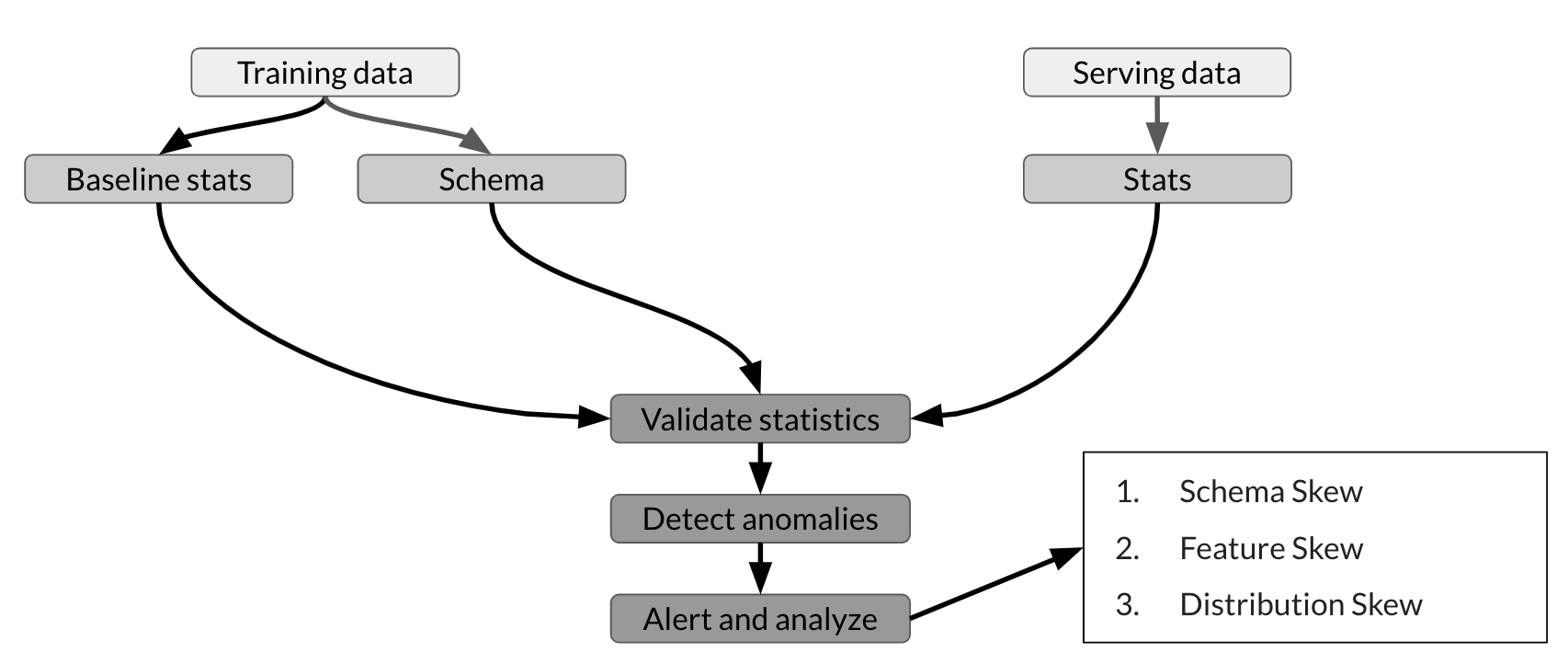
As shown, you can use TFDV to compute descriptive statistics of the training data and generate a schema. You can then validate new datasets (e.g. the serving dataset from your customers) against this schema to detect and fix anomalies. This helps prevent the different types of skew. That way, you can be confident that your model is training on or predicting data that is consistent with the expected feature types and distribution.
This ungraded exercise demonstrates useful functions of TFDV at an introductory level as preparation for this week's graded programming exercise. Specifically, you will:
- Generate and visualize statistics from a dataset
- Detect and fix anomalies in an evaluation dataset
Let's begin!